










































The field of AI is advancing rapidly, especially in large language models. Prominent models like GPT-3 and GPT-4 have impressive capabilities in generating coherent, human-like text. However, these models face a significant limitation: they rely solely on the data they were trained on, often leading to outdated or contextually incorrect information. As a result, the quest for more accurate, real-time, and contextually aware models has led to the emergence of Retrieval Augmented Generation (RAG).
RAG combines the generative power of large language models with the precision of information retrieval systems. By augmenting the generative model’s responses with real-time, relevant data fetched from external knowledge bases, RAG opens up new possibilities for generating accurate, up-to-date, and contextually rich information. In this article, we’ll dive into what RAG is, how it works, and why it is a game-changer in the world of AI.
What is Retrieval Augmented Generation (RAG)?
At its core, Retrieval Augmented Generation is a hybrid approach that fuses two powerful AI techniques: information retrieval and text generation.
Traditional language models, such as GPT-3, rely on vast amounts of pre-trained data. While these models are adept at producing fluent and coherent responses, they are limited by the static nature of their training data. As a result, they may produce factually incorrect or outdated information, often referred to as “hallucinations.”
RAG addresses this limitation by incorporating a retriever component that pulls in real-time, relevant information from external knowledge sources. The generative model then processes this information, producing responses that are linguistically accurate and grounded in factual, up-to-date content. In other words, RAG enhances the response generation process by accessing current data, reducing the likelihood of producing incorrect or irrelevant outputs.
The concept is simple: instead of solely relying on a model’s “memory,” RAG taps into a dynamic source of knowledge to improve the quality of its outputs. This combination of retrieving information and generating text leads to a far more robust, accurate, and context-aware language model.
Key Components of RAG
To understand how RAG achieves its enhanced capabilities, it’s important to break down its three core components:
Retriever
The retriever is responsible for fetching relevant content from external data sources. These sources could be anything from a curated knowledge base (like Wikipedia) to domain-specific repositories (like legal documents or scientific papers). The retriever scans the available information and identifies which passages or documents are most relevant to the query. This step ensures that the model can access up-to-date and contextually appropriate data.
Generative Model
The generative model works in conjunction with the retriever to synthesize responses. Unlike standalone generative models, which rely solely on pre-trained data, the generative component of RAG integrates the retrieved information into its output. This results in responses that are coherent and factually accurate, addressing one of the major challenges faced by traditional language models.
Knowledge Base
The quality and scope of the knowledge base are critical to RAG’s success. Whether it’s an internal database, a collection of documents, or an open-source platform like Wikipedia, the knowledge base serves as the retriever’s resource pool. The richer and more diverse the knowledge base, the better the retriever can perform in delivering accurate information to the generative model.
How Does Retrieval Augmented Generation Work?
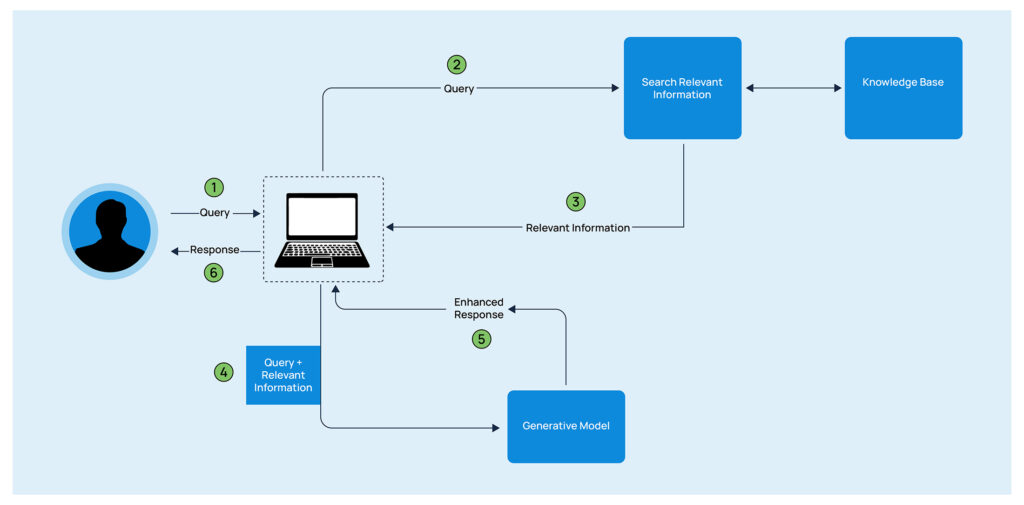
RAG operates in two key phases: retrieval and generation.
Retrieval
The first step in RAG is retrieving relevant information. When a query is made, the system doesn’t immediately generate a response like a traditional language model would. Instead, it first identifies and pulls data from a vast pool of external sources, such as a knowledge base, a document repository, or even the web.
This retrieval process is powered by retriever models, typically trained using techniques like dense passage retrieval (DPR). These models learn to efficiently search through vast amounts of unstructured text to locate passages or documents that are most likely to contain relevant information. The key is that the retriever does not provide a final answer—it merely presents the most relevant chunks of data to the generative model.
Generation
Once the relevant information is retrieved, the generative model steps in. The role of the generative model, often a transformer-based architecture like GPT-3 or GPT-4, is to synthesize a coherent, natural language response. It does this by combining the retrieved information with its own pre-trained knowledge.
The generative model takes into account the context of the query and the retrieved data, integrating them to produce a well-rounded response. This fusion of information retrieval and generation ensures that the model’s output is fluent, accurate, and up-to-date information.
Together, these two steps create a system that produces responses with higher accuracy and relevance than purely generative models. RAG effectively bridges the gap between static knowledge inherent in traditional models and dynamic, real-time information retrieval systems.
What Are the Benefits of Using Retrieval Augmented Generation (RAG) Over Standard Generative Models?
RAG offers several distinct advantages over traditional generative models, making it a powerful tool for a variety of applications. Some key benefits include:
Better Responses with Increased Accuracy
One of the most significant advantages of RAG is its ability to produce more accurate responses. By retrieving relevant data from external sources, RAG reduces the likelihood of generating incorrect or outdated information. This makes it ideal for applications that require up-to-date and factual content, such as customer support, research, and legal analysis.
Reduced Hallucination
Traditional language models sometimes generate information that seems plausible but is entirely fabricated. This phenomenon, known as “hallucination,” can be problematic in critical applications like healthcare or finance. RAG mitigates this issue by grounding its responses in real data retrieved from reliable sources, resulting in more trustworthy outputs.
Context-Awareness
RAG’s retrieval mechanism allows it to provide more contextually relevant responses. Instead of generating generic answers based solely on pre-trained knowledge, the model tailors its output based on the specific information retrieved from external data sources. This leads to a more personalized and context-aware user experience.
Dynamic Knowledge Access
Unlike traditional models that require retraining to incorporate new data, RAG can access dynamic, real-time information without the need for extensive retraining. This flexibility allows it to adapt to new developments, such as changes in legal regulations, market trends, or scientific discoveries, making it more suitable for industries where information is constantly evolving.
Conclusion
Retrieval Augmented Generation represents a significant leap forward in the evolution of AI language models. By combining the strengths of information retrieval systems with the power of generative models, RAG produces responses that are not only coherent and contextually relevant but also grounded in accurate, up-to-date information. This hybrid approach has the potential to revolutionize a wide range of industries, from customer support and legal analysis to research and education.
As the availability of large, diverse datasets continues to grow and retrieval mechanisms improve, RAG will likely become an essential tool in the AI toolkit. Its ability to dynamically integrate new information, reduce hallucination, and provide context-aware responses makes it a promising solution for the next generation of AI-powered applications. The future of language models is not just about generating text—it’s about generating the right text, and RAG is leading the way in this exciting new frontier.
Are you ready to take the next step toward call automation with Conversational AI? Schedule a free demo with one of our experts to learn more!





